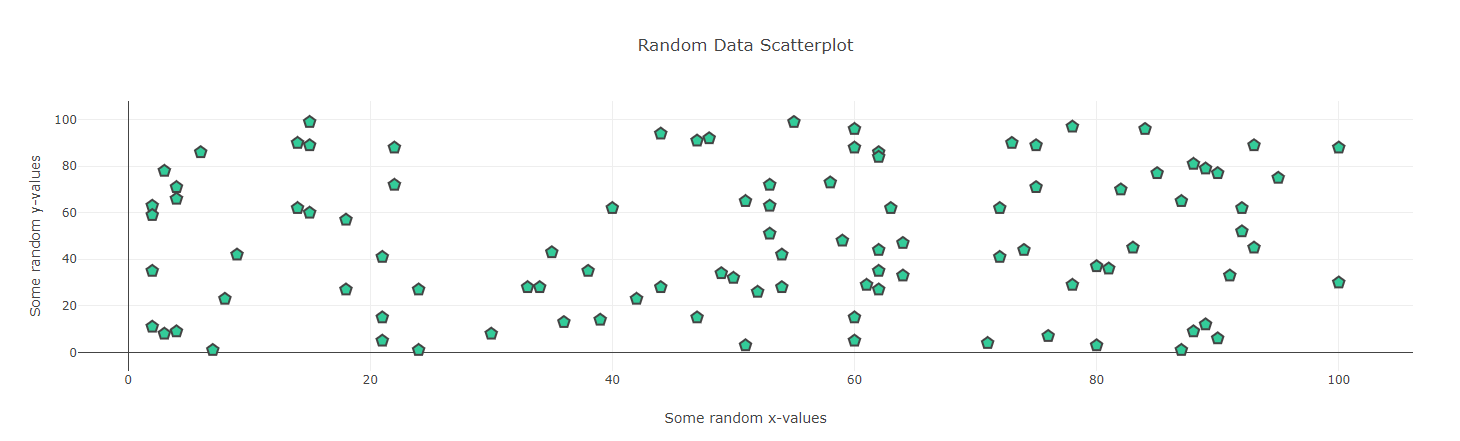
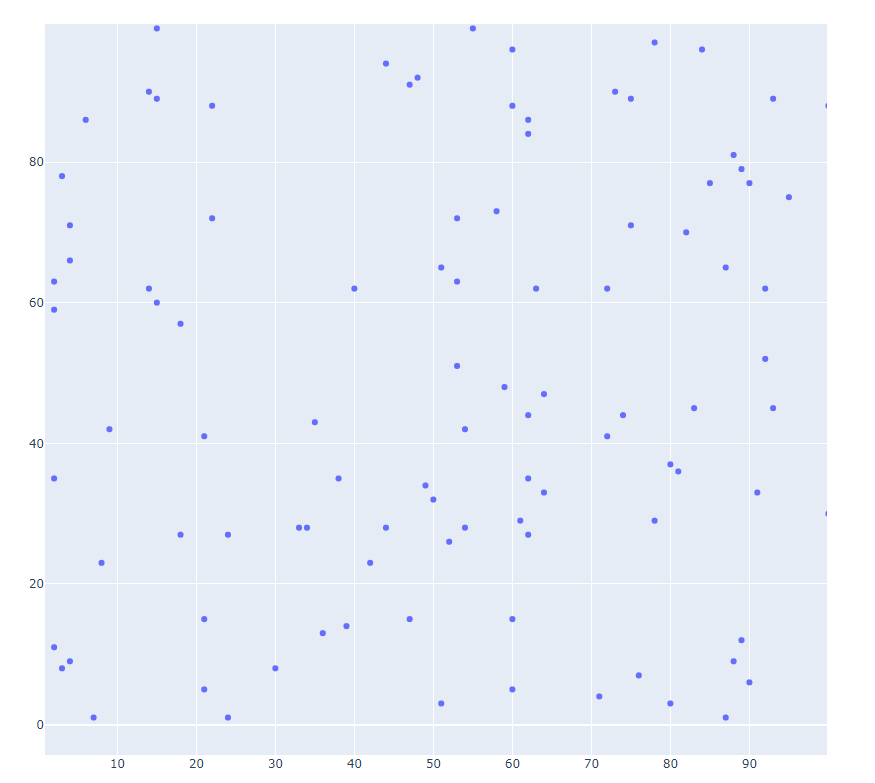
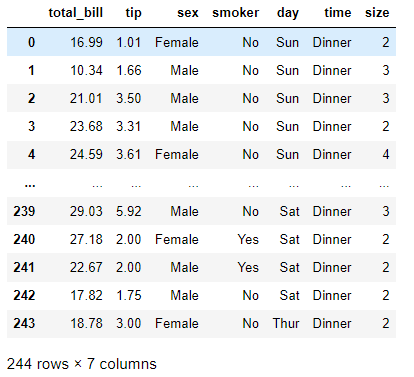
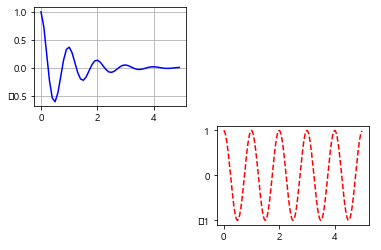
- liveupdating1.py ####### # This script will make regular API calls to http://data-live.flightradar24.com # to obtain updated total worldwide flights data. # **This version only loads the site. No callbacks.** ###### import dash import dash_core_components as dcc import dash_html_components as html from dash.dependencies import Input, Output import plotly.graph_objs as go import requests url = ..