## 1H ## RatingCounter
- ratings-counter.py
from pyspark import SparkConf, SparkContext
import collections
conf = SparkConf().setMaster("local").setAppName("RatingHistogram")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/ml-100k/u.data")
ratings = lines.map(lambda x : x.split()[2])
result = ratings.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print("%s %i" %(key, value))Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
1 6110
2 11370
3 27145
4 34174
5 21201
- SparkConf().setMaster("local").setAppName("RatingsHistogram")
- 싱글 클러스터
- sc = SparkContext(conf = conf)
- 설정한 conf를 SparkContext로 설정. 일종의 환경설정
- lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/ml-100k/u.data") // 10 만개의 데이터 행단위로 불러옴
- Load the Data
- ratings = lines.map(lambda x : x.split()[2])
- Extract(Map) the Data We care about
- key에 의해 sorting된 결과를 볼 수 있음
Transformations와 Actions의 차이 : RDD에서 RDD / RDD에서 스칼라 같은 새로운 데이터 타입을 만드는지
spark-submit 하기 전에 spark-shell
http://localhost:4040/jobs/ 에서 볼 수 있음
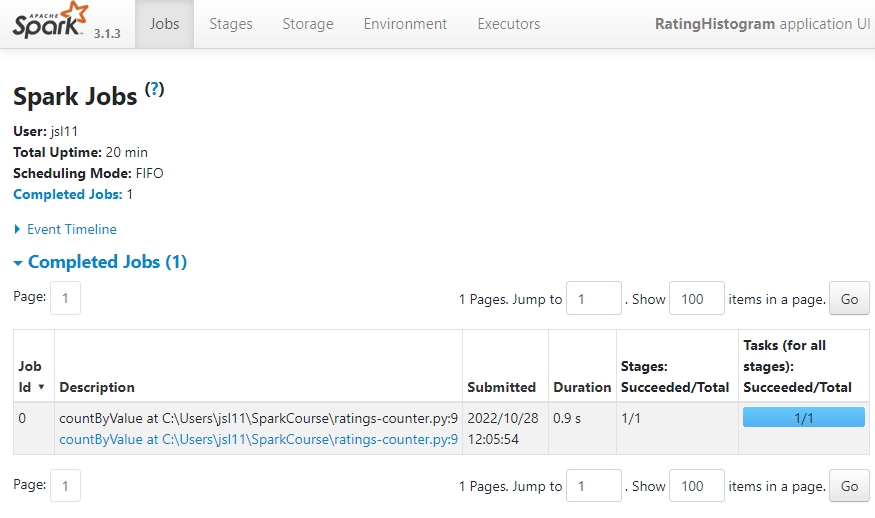
## Assign 02 ##
u.user 에서 1) 나이 별로 빈도를 출력하시오. 2) 성별로 빈도를 출력하시옹.
from pyspark import SparkConf, SparkContext
import collections
conf = SparkConf().setMaster("local").setAppName("RatingHistogram")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/ml-100k/u.user")
# ratings = lines.map(lambda x : x.split("|")[2])
ratings = lines.map(lambda x : x.split("|")[1])
result = ratings.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print("%s %i" %(key, value))## 2H ## Friends by Age
friends by age - 연령별로 친구들의 수를 계산하는 예제
key : age, value : number of friends
- reduceBykey() : 키에 의해 축소됨
- groupByKey() : 같은 키에 대해 그룹으로 묶어줌
- sortByKey() : key value에 의해 RDD 정렬
- keys(), Values() : 새로운 RDD를 만드는 데, key로만 이루어진, value로만 이루어진
- mapValues(), flatMapValues()
Input : ID, name, age, number of friends (쉼표로 구분)
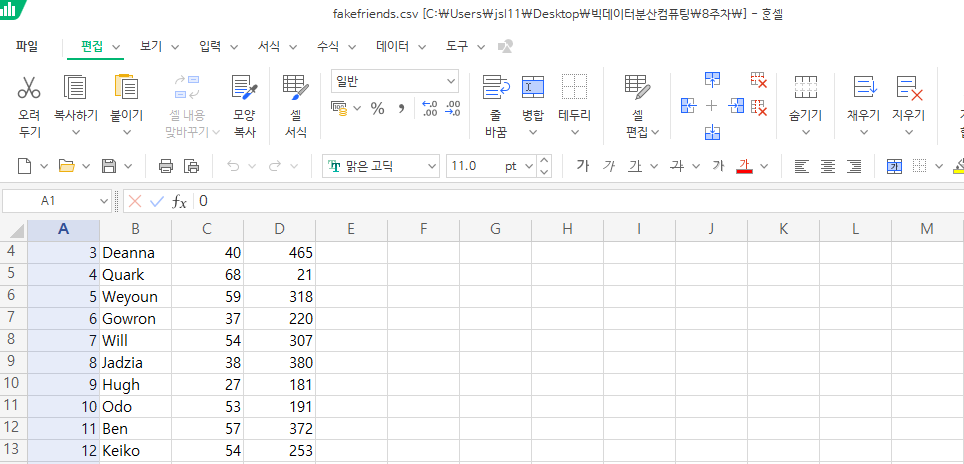
- friends-by-age.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("FriendsByAge")
sc = SparkContext(conf = conf)
def parseLine(line):
fields = line.split(',')
age = int(fields[2])
numFriends = int(fields[3])
return (age, numFriends)
lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/fakefriends.csv")
rdd = lines.map(parseLine)
totalsByAge = rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
averagesByAge = totalsByAge.mapValues(lambda x: x[0] / x[1])
results = averagesByAge.collect()
for result in results:
print(result)- mapValues(lambda x: (x, 1))
- (33, 385) => (33, (385, 1))
- (33, 2) => (33, (2, 1))
- reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
- 키가 고정되고 같은 것끼리 value 값을 더해줌
- (33, 385) => (33, (385, 1))
- (33, 2) => (33, (2, 1))
- ==> (33, (387, 2))
- averagesByAge = totalsByAge.mapValues(lambda x: x[0] / x[1])
- 평균을 구해줌
- (33, (387, 2)) ==> (33, 193.5)
- averagesByAge.collect()
- 모아서 저장 후 출력
- totalsByAge = rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
- mapValues 먼저 실행 후 reduceByKey 실행됨
C:\Users\jsl11\SparkCourse>spark-submit friends-by-age.py
(33, 325.3333333333333)
(26, 242.05882352941177)
(55, 295.53846153846155)
(40, 250.8235294117647)
(68, 269.6)
(59, 220.0)
(37, 249.33333333333334)
(54, 278.0769230769231)
(38, 193.53333333333333)
(27, 228.125)
(53, 222.85714285714286)
(57, 258.8333333333333)
(56, 306.6666666666667)
(43, 230.57142857142858)
(36, 246.6)
(22, 206.42857142857142)
(35, 211.625)
(45, 309.53846153846155)
(60, 202.71428571428572)
(67, 214.625)
(19, 213.27272727272728)
(30, 235.8181818181818)
(51, 302.14285714285717)
(25, 197.45454545454547)
(21, 350.875)
(42, 303.5)
(49, 184.66666666666666)
(48, 281.4)
(50, 254.6)
(39, 169.28571428571428)
(32, 207.9090909090909)
(58, 116.54545454545455)
(64, 281.3333333333333)
(31, 267.25)
(52, 340.6363636363636)
(24, 233.8)
(20, 165.0)
(62, 220.76923076923077)
(41, 268.55555555555554)
(44, 282.1666666666667)
(69, 235.2)
(65, 298.2)
(61, 256.22222222222223)
(28, 209.1)
(66, 276.44444444444446)
(46, 223.69230769230768)
(29, 215.91666666666666)
(18, 343.375)
(47, 233.22222222222223)
(34, 245.5)
(63, 384.0)
(23, 246.3)
- friends-by-age_sort.py
results_sort = averagesByAge.sortByKey()
results = results_sort.collect()C:\Users\jsl11\SparkCourse>spark-submit friends-by-age_sort.py
(18, 343.375)
(19, 213.27272727272728)
(20, 165.0)
(21, 350.875)
(22, 206.42857142857142)
(23, 246.3)
(24, 233.8)
(25, 197.45454545454547)
(26, 242.05882352941177)
(27, 228.125)
(28, 209.1)
(29, 215.91666666666666)
(30, 235.8181818181818)
(31, 267.25)
(32, 207.9090909090909)
(33, 325.3333333333333)
(34, 245.5)
(35, 211.625)
(36, 246.6)
(37, 249.33333333333334)
(38, 193.53333333333333)
(39, 169.28571428571428)
(40, 250.8235294117647)
(41, 268.55555555555554)
(42, 303.5)
(43, 230.57142857142858)
(44, 282.1666666666667)
(45, 309.53846153846155)
(46, 223.69230769230768)
(47, 233.22222222222223)
(48, 281.4)
(49, 184.66666666666666)
(50, 254.6)
(51, 302.14285714285717)
(52, 340.6363636363636)
(53, 222.85714285714286)
(54, 278.0769230769231)
(55, 295.53846153846155)
(56, 306.6666666666667)
(57, 258.8333333333333)
(58, 116.54545454545455)
(59, 220.0)
(60, 202.71428571428572)
(61, 256.22222222222223)
(62, 220.76923076923077)
(63, 384.0)
(64, 281.3333333333333)
(65, 298.2)
(66, 276.44444444444446)
(67, 214.625)
(68, 269.6)
(69, 235.2)
## Assign 03 ##
1) 나이 기준으로 정렬되어있는 프로그램을 친구 수 기준으로 정렬해서 출력하시오.
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("FriendsByAge")
sc = SparkContext(conf = conf)
def parseLine(line):
fields = line.split(',')
age = int(fields[2])
numFriends = int(fields[3])
return (age, numFriends)
lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/fakefriends.csv")
rdd = lines.map(parseLine)
totalsByAge = rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
averagesByAge = totalsByAge.mapValues(lambda x: x[0] / x[1])
results = averagesByAge.collect()
result_sort = sorted(results, key=lambda x: x[1])
for result in result_sort:
print(result)(58, 116.54545454545455)
(20, 165.0)
(39, 169.28571428571428)
(49, 184.66666666666666)
(38, 193.53333333333333)
(25, 197.45454545454547)
(60, 202.71428571428572)
(22, 206.42857142857142)
(32, 207.9090909090909)
(28, 209.1)
(35, 211.625)
(19, 213.27272727272728)
(67, 214.625)
(29, 215.91666666666666)
(59, 220.0)
(62, 220.76923076923077)
(53, 222.85714285714286)
(46, 223.69230769230768)
(27, 228.125)
(43, 230.57142857142858)
(47, 233.22222222222223)
(24, 233.8)
(69, 235.2)
(30, 235.8181818181818)
(26, 242.05882352941177)
(34, 245.5)
(23, 246.3)
(36, 246.6)
(37, 249.33333333333334)
(40, 250.8235294117647)
(50, 254.6)
(61, 256.22222222222223)
(57, 258.8333333333333)
(31, 267.25)
(41, 268.55555555555554)
(68, 269.6)
(66, 276.44444444444446)
(54, 278.0769230769231)
(64, 281.3333333333333)
(48, 281.4)
(44, 282.1666666666667)
(55, 295.53846153846155)
(65, 298.2)
(51, 302.14285714285717)
(42, 303.5)
(56, 306.6666666666667)
(45, 309.53846153846155)
(33, 325.3333333333333)
(52, 340.6363636363636)
(18, 343.375)
(21, 350.875)
(63, 384.0)
## 3H ##
1) Filtering RDD's (Weather Data)
특정한 조건(데이터 중 "TMIN"이라는 값일 때)에 해당되는 데이터만 추출
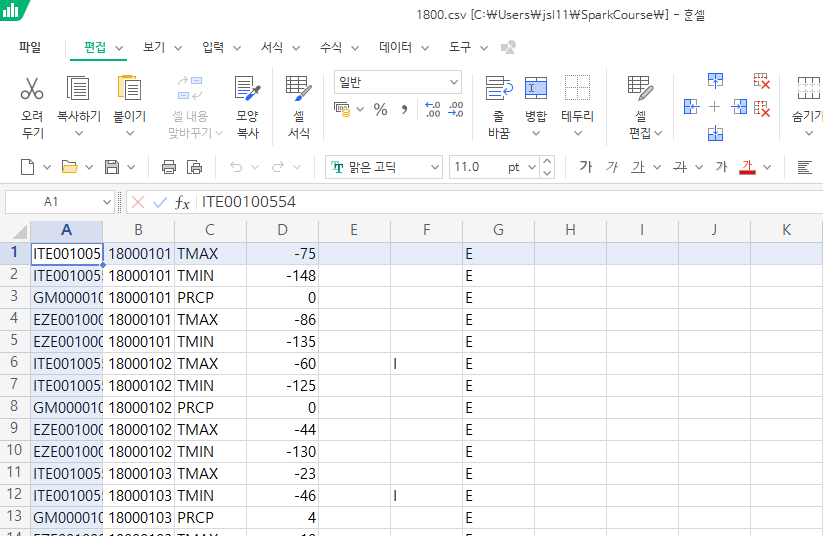
- min-temperatures.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("MinTemperatures")
sc = SparkContext(conf = conf)
def parseLine(line):
fields = line.split(',')
stationID = fields[0]
entryType = fields[2]
temperature = float(fields[3]) * 0.1 * (9.0 / 5.0) + 32.0
return (stationID, entryType, temperature)
lines = sc.textFile("file:///SparkCourse/1800.csv")
parsedLines = lines.map(parseLine)
minTemps = parsedLines.filter(lambda x: "TMIN" in x[1])
stationTemps = minTemps.map(lambda x: (x[0], x[2]))
minTemps = stationTemps.reduceByKey(lambda x, y: min(x,y))
results = minTemps.collect();
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))- minTemps = parsedLines.filter(lambda x: "TMIN" in x[1])
- TMIN이라는 값을 찾아 minTemps에 저장
- stationTemps = minTemps.map(lambda x: (x[0], x[2]))
- minTemps를 x[0]와 x[2]로 매핑
- key / value pairs (stationID, Temperature)
- minTemps = stationTemps.reduceByKey(lambda x, y: min(x,y))
C:\Users\jsl11\SparkCourse>spark-submit min-temperatures.py
ITE00100554 5.36F
EZE00100082 7.70F
- max-temperatures.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("MinTemperatures")
sc = SparkContext(conf = conf)
def parseLine(line):
fields = line.split(',')
stationID = fields[0]
entryType = fields[2]
temperature = float(fields[3]) * 0.1 * (9.0 / 5.0) + 32.0
return (stationID, entryType, temperature)
lines = sc.textFile("file:///C:/Users/jsl11/SparkCourse/1800.csv")
parsedLines = lines.map(parseLine)
maxTemps = parsedLines.filter(lambda x: "TMAX" in x[1])
stationTemps = maxTemps.map(lambda x: (x[0], x[2]))
maxTemps = stationTemps.reduceByKey(lambda x, y: max(x,y))
results = maxTemps.collect();
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))C:\Users\jsl11\SparkCourse>spark-submit max-temperatures.py
ITE00100554 90.14F
EZE00100082 90.14F
2) Map vs FlatMap
- Map : 각각의 원소를 하나의 RDD element로 생성시켜줌
- ex. The quick red fox jumped
- line = lines.map(lambda x : x.upper()) ==> THE QUICK RED FOX JUMPED ( 한 덩어리 )
- FlatMap : 각각을 이용해 많은 수의 새로운 element를 생성시켜줌
- ex. The quick red fox jumped
- line = lines.flatMap(lambda x : x.split()) ==> The quick red fox jumped ( 각각의 단어가 하나의 element가 됨 )
- word-count.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("WordCount")
sc = SparkContext(conf = conf)
input = sc.textFile("file:///C:/Users/jsl11/SparkCourse/in/word_count.text")
words = input.flatMap(lambda x: x.split())
wordCounts = words.countByValue()
for word, count in wordCounts.items():
cleanWord = word.encode('ascii', 'ignore')
if (cleanWord):
print(cleanWord.decode() + " " + str(count))...
...
nationally 1
globallyrenowned. 1
manufacturing 1
eroded 1
restructuring 1
industry, 1
transitioned 1
into 1
industries. 1
September 1
11 1
attacks 2
2001 1
destroyed 1
Trade 1
Center, 1
killing 1
almost 1
3,000 1
people; 1
they 1
largest 1
terrorist 1
on 1
soil. 1
3) Improving Word Count
대소문자, 콤마, 마침표 문제 ==> 자연어 처리 같은 데이터 정규화, 결과 정렬
- wort-count-better.py
import re
from pyspark import SparkConf, SparkContext
def normalizeWords(text):
return re.compile(r'\W+', re.UNICODE).split(text.lower())
conf = SparkConf().setMaster("local").setAppName("WordCount")
sc = SparkContext(conf = conf)
input = sc.textFile("file:///C:/Users/jsl11/SparkCourse/in/word_count.text")
words = input.flatMap(normalizeWords)
wordCounts = words.countByValue()
for word, count in wordCounts.items():
cleanWord = word.encode('ascii', 'ignore')
if (cleanWord):
print(cleanWord.decode() + " " + str(count))...
...
nationally 1
globallyrenowned 1
manufacturing 1
eroded 1
restructuring 1
industry 1
transitioned 1
into 1
september 1
11 1
attacks 2
2001 1
destroyed 1
killing 1
almost 1
3 1
people 1
they 1
largest 1
terrorist 1
on 1
soil 1
4) Sorting the Results
- wort-count-better-sorted.py
import re
from pyspark import SparkConf, SparkContext
def normalizeWords(text):
return re.compile(r'\W+', re.UNICODE).split(text.lower())
conf = SparkConf().setMaster("local").setAppName("WordCount")
sc = SparkContext(conf = conf)
input = sc.textFile("file:///C:/Users/jsl11/SparkCourse/in/word_count.text")
words = input.flatMap(normalizeWords)
wordCounts = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
wordCountsSorted = wordCounts.map(lambda x: (x[1], x[0])).sortByKey()
results = wordCountsSorted.collect()
for result in results:
count = str(result[0])
word = result[1].encode('ascii', 'ignore')
if (word):
print(word.decode() + ":\t\t" + count)opened: 3
world: 3
around: 4
trade: 4
century: 4
during: 4
united: 4
states: 4
first: 5
as: 5
s: 6
became: 6
war: 6
state: 7
was: 8
from: 8
city: 10
a: 11
to: 17
york: 20
new: 21
and: 21
in: 24
of: 33
the: 81
==> 모두 소문자로 변환되어 있음
## Assign 04 ##
역순으로 sort 후 출력
import re
from pyspark import SparkConf, SparkContext
def normalizeWords(text):
return re.compile(r'\W+', re.UNICODE).split(text.lower())
conf = SparkConf().setMaster("local").setAppName("WordCount")
sc = SparkContext(conf = conf)
input = sc.textFile("file:///C:/Users/jsl11/SparkCourse/in/word_count.text")
words = input.flatMap(normalizeWords)
wordCounts = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
wordCountsSorted = wordCounts.map(lambda x: (x[1], x[0])).sortByKey()
results = wordCountsSorted.collect()
results_ = sorted(results, key = lambda x : x[0], reverse=True)
for result in results_:
count = str(result[0])
word = result[1].encode('ascii', 'ignore')
if (word):
print(word.decode() + ":\t\t" + count)Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
the: 81
of: 33
in: 24
new: 21
and: 21
york: 20
to: 17
a: 11
city: 10
was: 8
from: 8
state: 7
s: 6
became: 6
war: 6
first: 5
as: 5
around: 4
trade: 4
century: 4
during: 4
united: 4
states: 4
...
...
'CLASS > Spark,Hadoop,Docker,Data Visualization' 카테고리의 다른 글
| [빅데이터분산컴퓨팅] 2022.11.08 Categorical Data Ploting, Seaborn, zomata.csv ploting (0) | 2022.11.08 |
|---|---|
| [빅데이터분산컴퓨팅] 2022.11.01 numpy, pandas, seaborn (2) | 2022.11.01 |
| [빅데이터분산컴퓨팅] 2022.10.18 pyspark word count 예제 (0) | 2022.10.18 |
| [빅데이터분산컴퓨팅] 2022.10.11 pyspark 환경 설정, word-count.py 실행 (0) | 2022.10.11 |
| [빅데이터분산컴퓨팅] 2022.10.04 spark 설치 (4) | 2022.10.04 |