# sample_df1, sample_df2, ldf, rdf
# sample dataFrame 1
Person = collections.namedtuple('Person', 'name age job')
row1 = Person(name="hayoon", age=7, job="student")
row2 = Person(name="sunwoo", age=13, job="student")
row3 = Person(name="hajoo", age=5, job="kindergartener")
row4 = Person(name="jinwoo", age=13, job="student")
data = [row1, row2, row3, row4]
sample_df = spark.createDataFrame(data)
# sample dataFrame 2
d1 = ("store2", "note", 20, 2000)
d2 = ("store2", "bag", 10, 5000)
d3 = ("store1", "note", 15, 1000)
d4 = ("store1", "pen", 20, 5000)
sample_df2 = spark.createDataFrame([d1, d2, d3, d4]).toDF("store", "product", "amount", "price")
ldf = spark.createDataFrame([Word("w1", 1), Word("w2", 1)])
rdf = spark.createDataFrame([Word("w1", 1), Word("w3", 1)])
# runMaxMin(spark, df)
def runMaxMin(spark, df):
min_col = min("age")
max_col = max("age")
df.select(min_col, max_col).show()
# runMaxMin(spark, sample_df)
# runAggregateFunctions(spark, df1, df2) - 집계 함수
def runAggregateFunctions(spark, df1, df2):
# collect_list, collect_set
doubledDf1 = df1.union(df1)
doubledDf1.select(functions.collect_list(doubledDf1["name"])).show(truncate=False)
doubledDf1.select(functions.collect_set(doubledDf1["name"])).show(truncate=False)
# count, countDistinct
doubledDf1.select(functions.count(doubledDf1["name"]), functions.countDistinct(doubledDf1["name"])).show(
truncate=False)
# sum
df2.printSchema()
df2.select(sum(df2["price"])).show(truncate=False)
# grouping, grouping_id
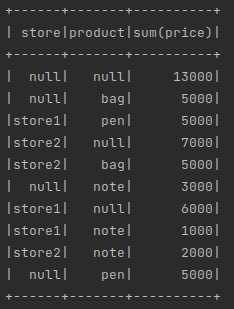
df2.cube(df2["store"], df2["product"]).agg(sum(df2["amount"]), grouping(df2["store"])).show(truncate=False)
df2.cube(df2["store"], df2["product"]).agg(sum(df2["amount"]), grouping_id(df2["store"], df2["product"])).show(
truncate=False)
runAggregateFunctions(spark, sample_df, sample_df2)
runAggregateFunctions 결과
# runOtherFunctions(spark, df)
def runOtherFunctions(spark, personDf):
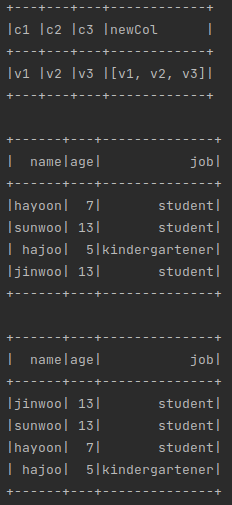
df = spark.createDataFrame([("v1", "v2", "v3")], ["c1", "c2", "c3"]);
# array
df.select(df.c1, df.c2, df.c3, array("c1", "c2", "c3").alias("newCol")).show(truncate=False)
# desc, asc
personDf.show()
personDf.sort(functions.desc("age"), functions.asc("name")).show()
# pyspark 2.1.0 버전은 desc_nulls_first, desc_nulls_last, asc_nulls_first, asc_nulls_last 지원하지 않음
# split, length (pyspark에서 컬럼은 df["col"] 또는 df.col 형태로 사용 가능)
df2 = spark.createDataFrame([("Splits str around pattern",)], ['value'])
df2.select(df2.value, split(df2.value, " "), length(df2.value)).show(truncate=False)
# rownum, rank
f1 = StructField("date", StringType(), True)
f2 = StructField("product", StringType(), True)
f3 = StructField("amount", IntegerType(), True)
schema = StructType([f1, f2, f3])
p1 = ("2017-12-25 12:01:00", "note", 1000)
p2 = ("2017-12-25 12:01:10", "pencil", 3500)
p3 = ("2017-12-25 12:03:20", "pencil", 23000)
p4 = ("2017-12-25 12:05:00", "note", 1500)
p5 = ("2017-12-25 12:05:07", "note", 2000)
p6 = ("2017-12-25 12:06:25", "note", 1000)
p7 = ("2017-12-25 12:08:00", "pencil", 500)
p8 = ("2017-12-25 12:09:45", "note", 30000)
dd = spark.createDataFrame([p1, p2, p3, p4, p5, p6, p7, p8], schema)
w1 = Window.partitionBy("product").orderBy("amount")
w2 = Window.orderBy("amount")
dd.select(dd.product, dd.amount, functions.row_number().over(w1).alias("rownum"),
functions.rank().over(w2).alias("rank")).show()
runOtherFunctions(spark, sample_df)
# runAgg(spark, df)
def runAgg(spark, df):
df.agg(max("amount"), min("price")).show()
df.agg({"amount": "max", "price": "min"}).show()
runAgg(spark, sample_df2)
# runDfAlias(spark, df)
def runDfAlias(spark, df):
df.select(df["product"]).show()
df.alias("aa").select("aa.product").show()
runDfAlias(spark, sample_df2)
# runGroupBy(spark, df)
def runGroupBy(spark, df):
df.groupBy("store", "product").agg({"price": "sum"}).show()
# runGroupBy(spark, sample_df2)
# runCube(spark, df)
def runCube(spark, df):
df.cube("store", "product").agg({"price": "sum"}).show()
# runCube(spark, sample_df2)
# runDistinct(spark)
def runDistinct(spark):
d1 = ("store1", "note", 20, 2000)
d2 = ("store1", "bag", 10, 5000)
d3 = ("store1", "note", 20, 2000)
rows = [d1, d2, d3]
cols = ["store", "product", "amount", "price"]
df = spark.createDataFrame(rows, cols)
df.distinct().show()
df.dropDuplicates(["store"]).show()
# runDistinct(spark)
# runDrop(spark, df)
def runDrop(spark, df):
df.drop(df["store"]).show()
# runDrop(spark, sample_df2)
# runIntersect(spark)
def runIntersect(spark):
a = spark.range(1, 5)
b = spark.range(2, 6)
c = a.intersect(b)
c.show()
# runIntersect(spark)
# runExcept(spark)
def runExcept(spark):
df1 = spark.range(1, 6)
df2 = spark.createDataFrame([(2,), (4,)], ['value'])
# 파이썬의 경우 except 대신 subtract 메서드 사용
# subtract의 동작은 except와 같음
df1.subtract(df2).show()
# runExcept(spark)
# runJoin(spark, ldf, rdf)
def runJoin(spark, ldf, rdf):
joinTypes = "inner,outer,leftouter,rightouter,leftsemi".split(",")
for joinType in joinTypes:
print("============= %s ===============" % joinType)
ldf.join(rdf, ["word"], joinType).show()
# runJoin(spark, ldf, rdf)
# runNa(spark, ldf, rdf)
def runNa(spark, ldf, rdf):
result = ldf.join(rdf, ["word"], "outer").toDF("word", "c1", "c2")
result.show()
# 파이썬의 경우 na.drop또는 dropna 사용 가능
# c1과 c2 칼럼의 null이 아닌 값의 개수가 thresh 이하일 경우 drop
# thresh=1로 설정할 경우 c1 또는 c2 둘 중의 하나만 null 아닌 값을 가질 경우
# 결과에 포함시킨다는 의미가 됨
result.na.drop(thresh=2, subset=["c1", "c2"]).show()
result.dropna(thresh=2, subset=["c1", "c2"]).show()
# fill
result.na.fill({"c1": 0}).show()
# 파이썬의 경우 to_replace에 딕셔너리를 지정하여 replace를 수행(이 경우 value에 선언한 값은 무시됨
# 딕셔너리를 사용하지 않을 경우 키 목록(첫번째 인자)과 값 목록(두번째 인자)을 지정하여 replace 수행
result.na.replace(to_replace={"w1": "word1", "w2": "word2"}, value="", subset="word").show()
result.na.replace(["w1", "w2"], ["word1", "word2"], "word").show()
# runNa(spark, ldf, rdf)
# runOrderBy(spark)
def runOrderBy(spark):
df = spark.createDataFrame([(3, "z"), (10, "a"), (5, "c")], ["idx", "name"])
df.orderBy("name", "idx").show()
df.orderBy("idx", "name").show()
# runOrderBy(spark)
# runRollup(spark, df)
def runRollup(spark, df):
df.rollup("store", "product").agg({"price": "sum"}).show();
runRollup(spark, sample_df2)
# runStat(spark)
def runStat(spark):
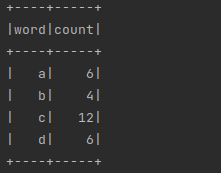
df = spark.createDataFrame([("a", 6), ("b", 4), ("c", 12), ("d", 6)], ["word", "count"])
df.show()
df.stat.crosstab("word", "count").show()
runStat(spark)
# runWithColumn(spark)
def runWithColumn(spark):
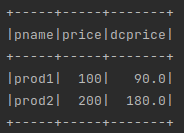
df1 = spark.createDataFrame([("prod1", "100"), ("prod2", "200")], ["pname", "price"])
df2 = df1.withColumn("dcprice", df1["price"] * 0.9)
df3 = df2.withColumnRenamed("dcprice", "newprice")
df1.show()
df2.show()
df3.show()
# runWithColumn(spark)